1. 动态字符串( simple dynamic string, SDS)
在 Redis 中,当需要可以被重复修改的字符串时,会使用 SDS 类型 ,而不是 C 语言中默认的 C 字符串类型 。举个例子:
SET msg "Hello World"
在这个语句中,Redis 会新建一个键值对,其中
- key 为一个 字符串,对象的底层实现是一个保存着字符串 “msg” 的 SDS 对象。
- value 为一个字符串,对象的底层实现是一个保存着字符串 “Hello World” 的 SDS 对象。
如果是 key 对多个 value 的情况下, 如
RPUSH fruits "apple" "banana" "cherry"
Redis 同样会新建一个键值对,其中
- key 为一个 字符串,对象的底层实现是一个保存着字符串 “fruits” 的 SDS 对象。
- value 为一个列表对象,包含着三个字符串对象,分别由三个 SDS 实现:第一个 SDS 保存着字符串 “apple” ,第二个 SDS 保存着字符串 “banana”,第三个 SDS 保存着字符串 “cherry”。
SDS 对象除了作为保存数据库值的字符串之外,还用作缓冲区,比如 AOF 模块中的 AOF 缓冲区,客户端的输入缓冲区等等。
2. SDS 的定义
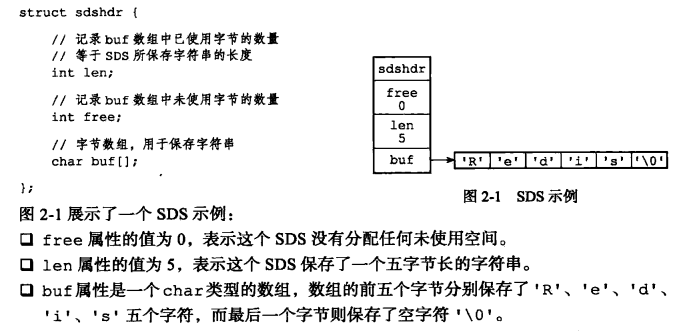
SDS 的结构如上图所示,len 表示字符串长度,需要注意的是,SDS 的 buf 数组也和 C 字符串一样保留着最后的空字符,而它的 len 计算时不会加上这个空字符,所以 "Redis\0" 在这里 len 值为 5。由于封装的原因,这里的 ‘\0’ 实际上虽然存在,但是使用者是完全不知道这里还有一个空字符的存在的,而这里加上空字符的原因也是为了可以让 SDS 沿用 一些 C 字符串函数库的函数。比如可以直接用 printf("%s", s->buf); 来打印 SDS 的字符串。
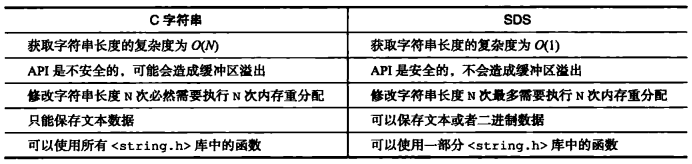
3. SDS 和 C 字符串的区别
- 传统的 C 字符串中,我们如果想要知道它的长度,需要遍历其一遍,直到遇到空字符为止,时间复杂度为 O(N)。而 SDS 可以直接取 len 的值,时间复杂度为 O(1)。
- 由于没有字符串的长度,C 字符串很容易导致缓冲区溢出,访问越界问题。
- C 字符串在使用的时候遇到空字符 ‘\0’ 便会认为字符串已经结束,一旦字符串中含有该字符则会导致字符串的异常截断,而 SDS 利用 len 字段可以防止这个情况。所以通过使用二进制安全的 SDS 可以存取任意数据。
- 拼接字符串时,C 字符串需要内存重分配拓展数组的大小,防止缓冲区溢出,截断字符串时,C 字符串需要内存重分配释放截断部分,防止内存泄漏。而 Redis 为了提高性能,增加了一个未使用空间的字段,通过该字段实现了空间预分配和惰性空间释放两种优化策略。
空间预分配策略:每次 SDS 进行空间扩展的时候,程序除了修改当前已有的空间,还会为 SDS 分配额外的空间,这也是 free 字段的作用,记录额外空间的长度,额外空间的长度分配有两种策略:根据修改后 SDS 的长度,即 len 属性的值,len 小于 1 MB 时,分配和 len 一样大小的额外空间, len 大于 1MB 时,则 分配 1 MB 的额外空间。举个例子, SDS 为 13 个字节,扩展 2 个字节后,len 变成 15 个字节,这时会分配额外的 15 个字节,free = 15;这时实际的字符串长度为 15 + 15 + 1 = 31。
惰性空间释放策略:当 SDS 进行缩短字符串的操作时,不马上进行内存重分配,而是利用 free 字段将这些截断的字符串长度记录下来,举个例子,如下图所示的 SDS 结构
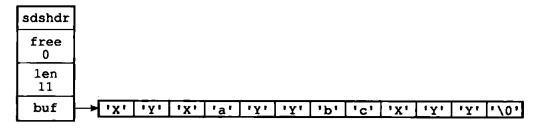
如果我们试图删除所有 “X” 和 “Y” 的字符, SDS 的结构会变成如下图所示。
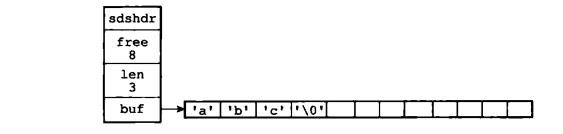
可以看到所有 “X” 和 “Y” 的字符长度总计为 8 ,这里 free 的值也被修改为 8。这时如果再对字符串进行增长的操作,则可以防止进行内存重分配的操作,而直接使用前面 “节约” 下来的内存。
4. 总结
之前遇到过一个二进制数据存取的问题 ,将 protobuf 序列化成二进制存到 Redis 数据库,然后取出来的时候并没有正常取出整个字符串,导致数据取出来之后反序列化异常,对比了存取时字符串的长度,发现就是因为 '\0' 字符导致的,后面通过加上字符串的长度去取字符串解决了这个问题。